Vidéos
CONTENU ASSOCIÉ
L’intelligence artificielle
Exemples d’IA et conclusion
Exemples d’IA en simulation
Présentation
2. Les réseaux de neurones
Quel est la définition d’un réseau de neurones, son rapport avec l’IA et comment ça marche ?
2.1. Qu’elle rapport avec l’IA ?
Dans cette partie nous allons voir le lien entre les réseaux de neurones et l’IA.

2.1.1. Intelligence artificielle, Machine Learning et Deep Learning ?
Intelligence Artificielle :
Conception de machine et de programmes capable de simuler l’intelligence artificielle
Basé sur des algorithmes programmables
Machine Learning :
Conception de programme capable d’apprendre sans avoir été explicitement programmé
Dérivé de l’IA, il intègre les statistiques
Deep Learning :
Conception de réseaux de neurones profonds permettant d’apprendre des notions complexes
Dérivé du DL, il intègre la neuroscience

2.1.2. Pourquoi le Machine Learning ?
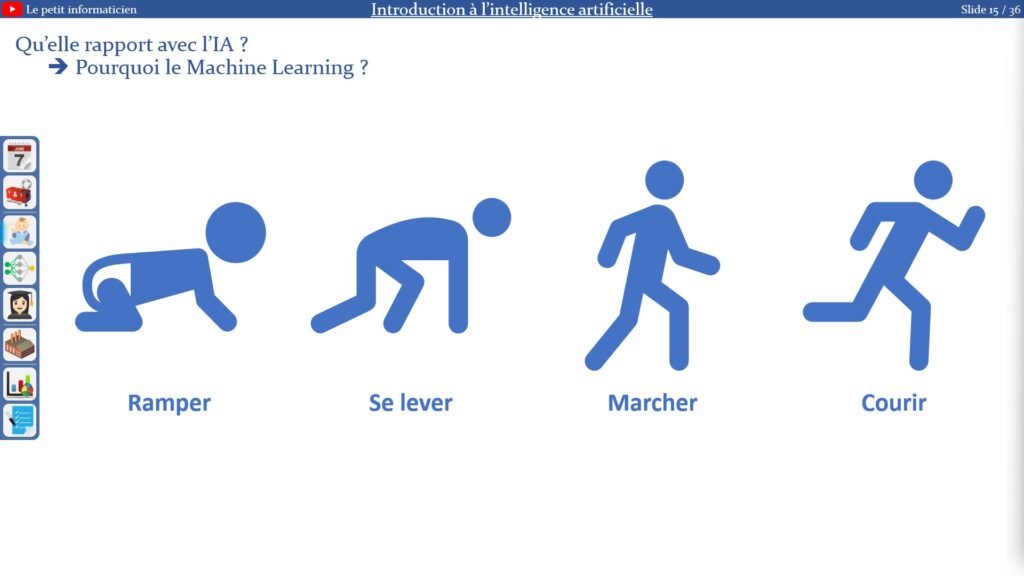
Exemple du bébé :
Comment un bébé apprend-il à marcher ?
– Le bébé rampe par terre
– Il se lève et tombe
– Puis se lève et fait quelques pas jusqu’à ses parents
– Avec l’entrainement il marche de plus en plus et tombe de moins en moins
– Enfin il finit par courir
Explication :
On n’apprend pas la physique, la répartition des masses et la gravité à un bébé pour qu’il sache comment marcher
Il a fini par savoir comment réagir pour contrôler son corps à force d’entrainement
Remarque :
Le ML est similaire, on ne code plus en dur mais on laisse le système apprendre
Cela permet une meilleure adaptabilité aux variations du système et, en général, de meilleurs résultats (car le système s’optimise)
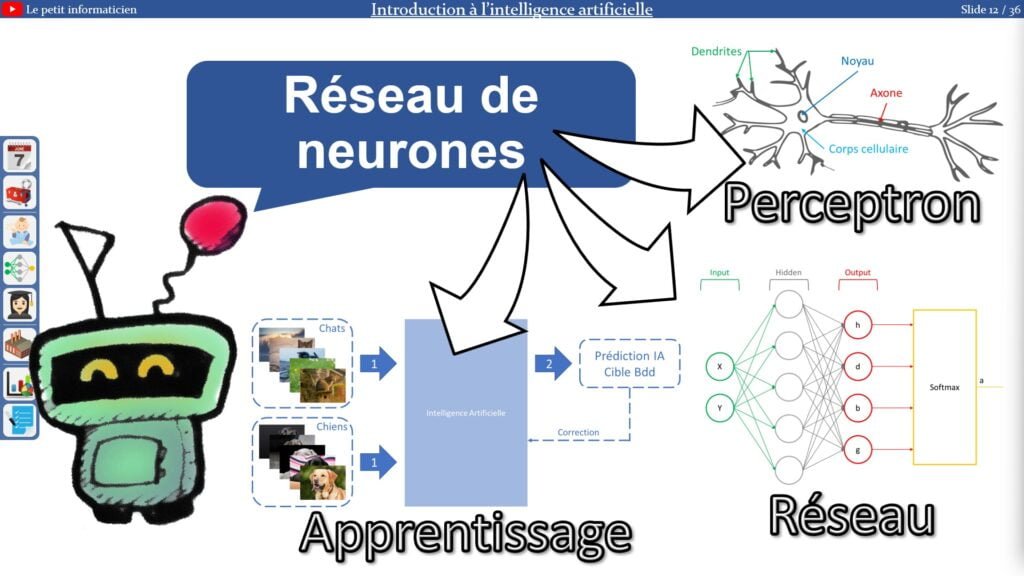
2.2. Qu’est-ce qu’un réseau de neurones ?
Dans cette seconde partie nous allons voir ce qu’est concrètement un réseau de neurones.

2.2.1. Le perceptron :
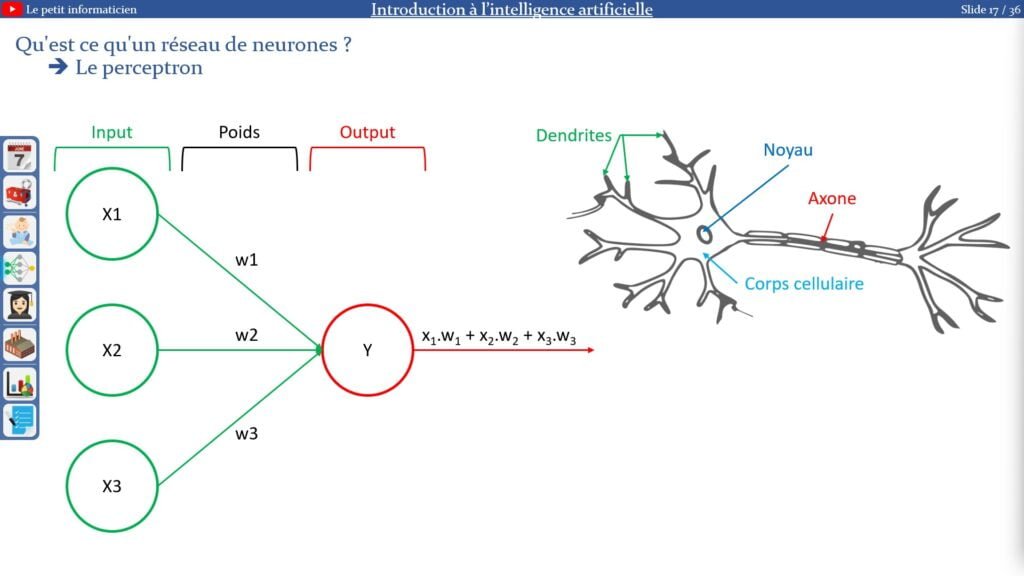
Un neurone :
Le perceptron est un réseau de neurones composé d’un neurone seul
– Il est composé de plusieurs entrées représentant les données provenant du système et d’une sortie
– La sortie se calcule en effectuant la somme pondérée des entrées par les poids associés
L’apprentissage :
L’apprentissage d’un neurone se fait en faisant évoluer ses poids afin de trouver en sortie le résultat le plus juste possible en fonction des entrées données
Lien avec la neuroscience :
Ce principe est repris du fonctionnement des neurones dans nos cerveaux, avec les dendrites représentant les entrées, le noyau pour faire le calcul et l’axone pour restituer le résultat à différentes branches qui se connecteront aux neurones suivants
2.2.2. Un réseau de neurones à une couche :
Les entrées :
Reprenant l’exemple du labyrinthe. On récupère de ce dernier la position sous forme de deux informations, x et y
Notre réseau aura ainsi 2entrées
Les sorties :
On peut effectuer 4 actions différentes, aller en haut, en bas, à droite et à gauche
Notre réseau aura ainsi 4 sortis
Les couches cachées :
Entre la couche d’entrée et la couche de sortie on aura différentes couches cachées (ici une seule couche de 5 neurones)
Plus le réseau est complexe, plus il pourra apprendre des environnements complexes, mais s’il l’ait trop, il va sur-apprendre et perdre en efficacité et justesse
La fonction d’activation :
Chaque neurone de sortie va avoir en résultat la probabilité d’être la meilleure action à exécuter
Une fonction d’activation (ici Softmax) va permettre de choisir en fonction de ces probabilités l’action la plus optimale

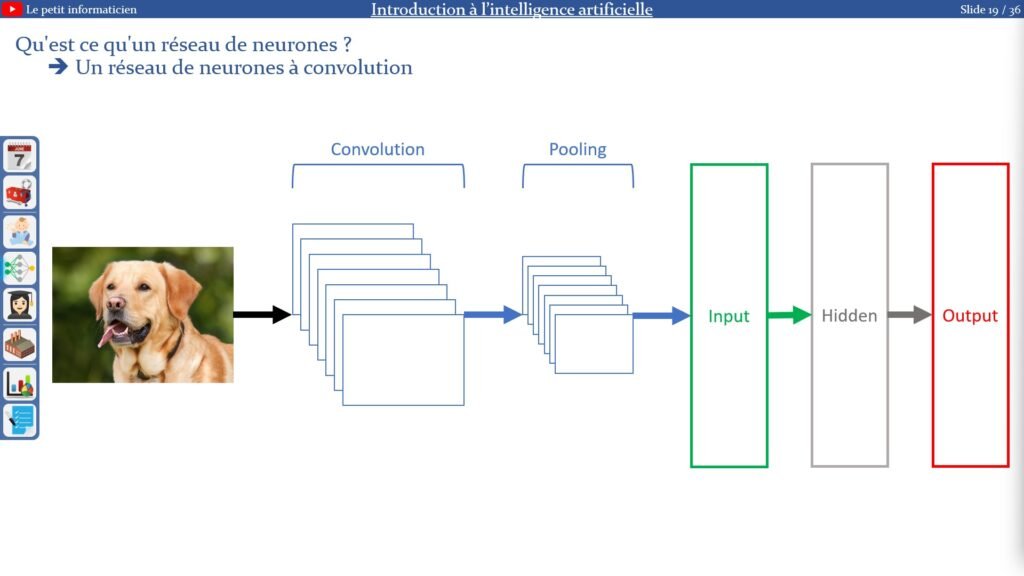
2.2.3. Un réseau de neurones à convolution :
La convolution :
La convolution permet d’appliquer des filtres sur les images afin d’en sortir des images plus petites permettant de détecter des features
Plus on applique de convolution, plus le réseau va être capable de détecter des features précis
Le pooling :
Le pooling permet de diminuer la taille des images et donc de réduire la consommation en calcul
Il part du principe que la position des paternes n’a pas d’importance, il supprime donc cette information
Et il permet de généraliser les informations et donc d’éviter que le réseau apprenne par cœur les images
Entrée du réseau :
On aplatit l’image pour n’avoir qu’un seul vecteur en entrée du réseau de neurones
2.3. Comment ça marche ?
Dans la troisième partie nous allons voir comment fonctionne les réseaux de neurones.

2.3.1. Apprentissage supervisé :
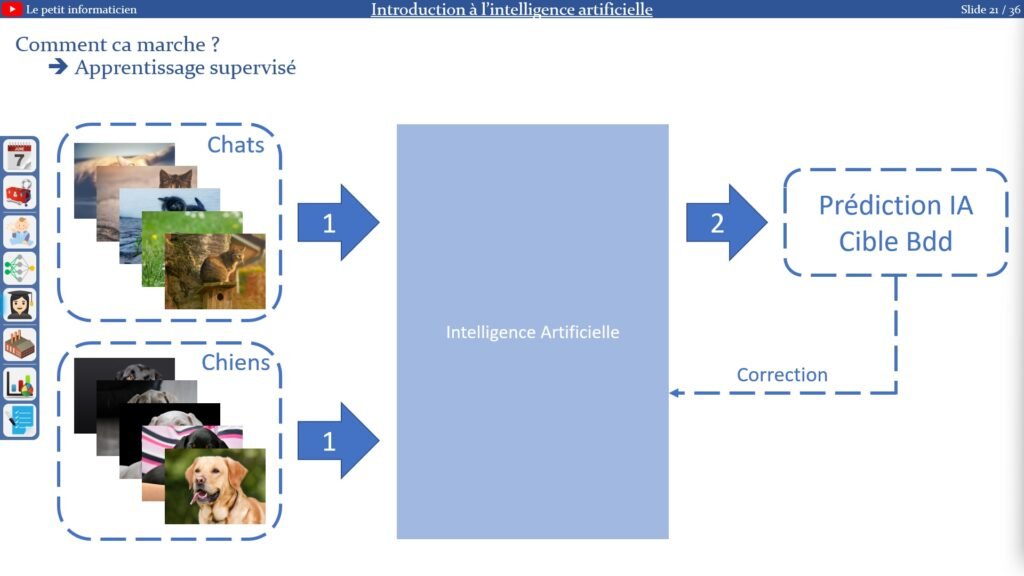
L’apprentissage :
On aide l’IA à comprendre ce que l’on cherche à obtenir :
– On lui donne des données brutes auxquelles on associe le résultat attendu (la cible)
– L’IA donne une prédiction
– Elle compare la prédiction avec la cible
– Puis se corrige elle-même
Remarque :
Les données brutes doivent être traitées initialement par un analyste
Il faut un grand nombre de données brutes pour apprendre
L’IA ne pourra pas être plus performante que l’analyste qui lui a fourni les données sources
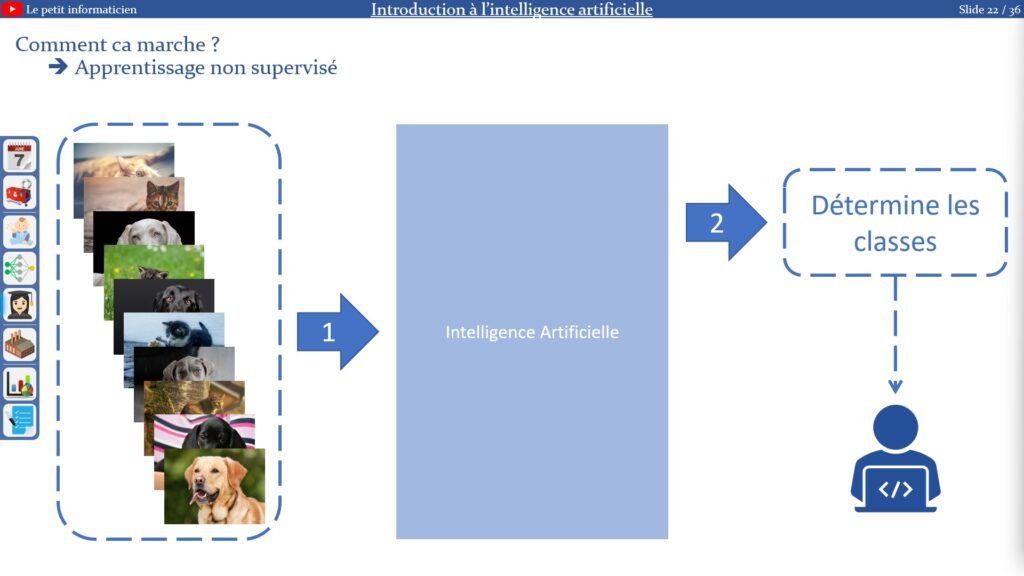
2.3.2. Apprentissage non supervisé :
L’apprentissage :
On laisse l’IA apprendre par elle-même :
– On donne à l’IA beaucoup de données brutes (sans cibles)
– L’IA détermine le nombre de classes et trie les données
– On analyse les classes données, on les tests pour savoir leurs correspondances…
Remarque :
On n’a aucune idée à l’avance des résultats proposés par l’IA
Idéalement on devrait avoir deux classes, une de chiens et une de chats, mais on pourrait avoir d’autres classes en fonction des features déterminer par l’IA
On peut découvrir des résultats que l’on n’arrive pas à comprendre, l’IA cherche les features cachés
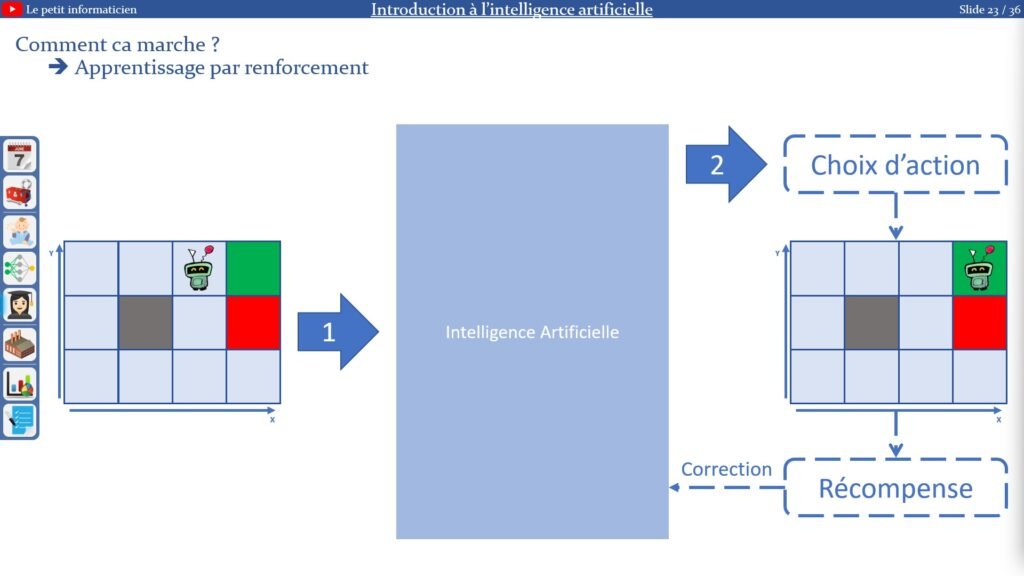
2.3.3. Apprentissage par renforcement :
L’apprentissage :
On laisse l’IA essayer :
– On envoie à l’IA les données de son environnement
– L’IA fait un choix selon les actions possibles
– L’action est effectuée dans l’environnement
– L’environnement renvoie une récompense en fonction du nouvel état
– La correction se fait en fonction de la récompense
Remarque :
La rétroaction est continue, plus on essaye et plus on explore l’environnement
L’apprentissage est continu, même s’il faut faire attention à certains paramètres
C’est ce type d’apprentissage qui est utilisé pour les jeux et chez l’homme